Python 3.12 introduced a new API for “sub interpreters”, which are a different parallel execution model for Python that provide a nice compromise between the true parallelism of multiprocessing, but with a much faster startup time. In this post, I’ll explain what a sub interpreter is, why it’s important for parallel code execution in Python and how it compares with other approaches.
What is a sub interpreter?¶
Python’s system architecture is roughly made up of three parts:
- A Python process, which contains one or more interpreters
- An interpreter, which contains a lock (the GIL) and one or more Python threads
- A thread, which contains information about the currently executing code.
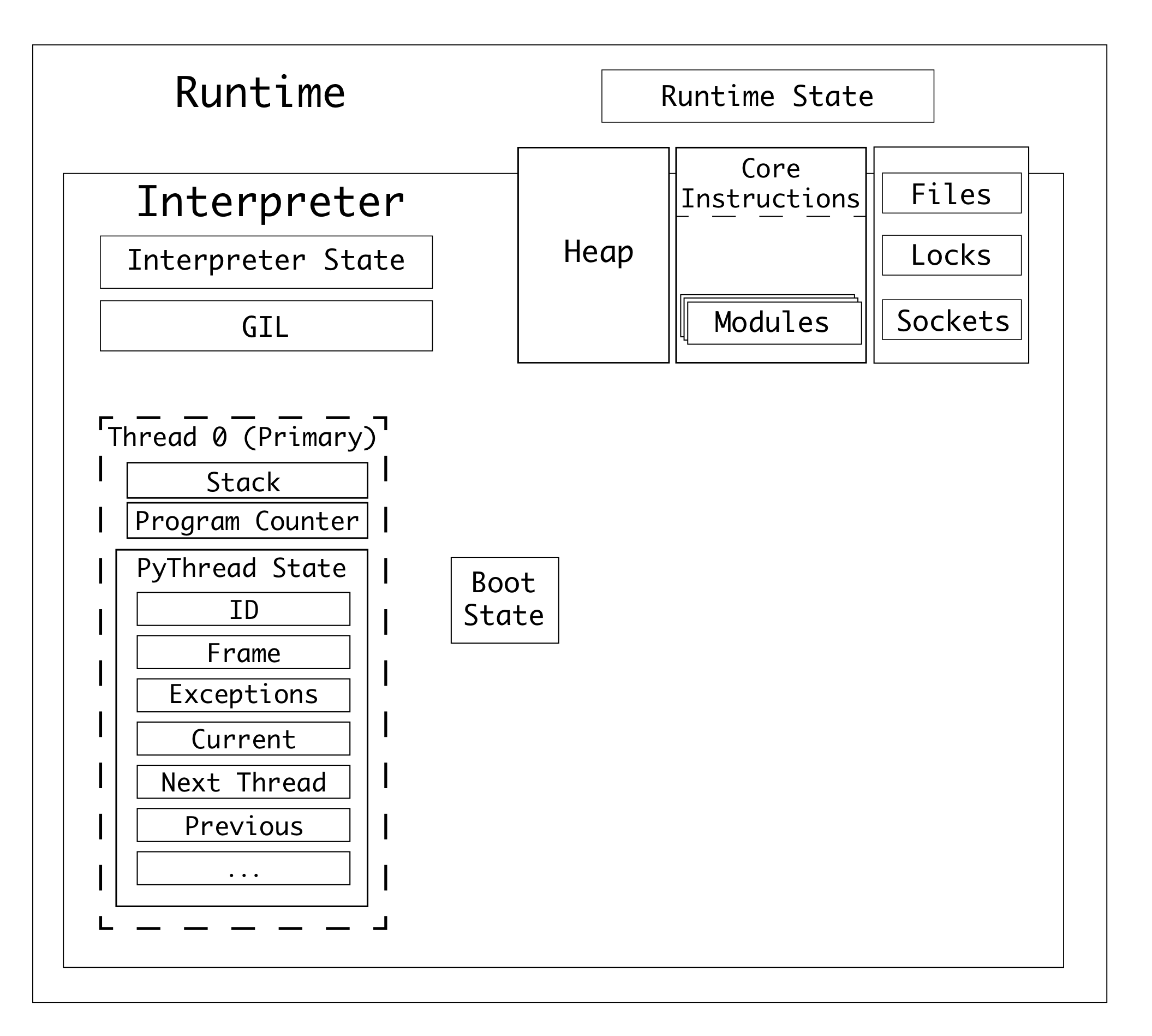
To learn more about this, you should read the “Parallelism and Concurrency” chapter of my book CPython Internals.
Since Python 1.5, there has been a C-API to have multiple interpreters, but this functionality was severely limited by the GIL and didn’t really enable true parallelism. As a consequence, the most commonly used technique for running code in parallel (without third party libraries) is to use the multiprocessing module.
In 2017, CPython core developers proposed to change the structure of interpreters so that the they were better isolated from the owning Python process and could operate in parallel. The actual work to achieve this was pretty huge (it isn’t finished 6 years later) and is split into two PEPs. PEP684 changes the GIL to be per-interpreter and PEP554 which provides an API to create interpreters and share data between them.
The GIL is the “Global Interpreter Lock”, a lock in a Python process that means that only 1 instruction can execute at any time in a Python process, even if it has multiple threads. This effectively means that even if you start 4 Python threads and run them concurrently on your nice 4-core CPU, only 1 thread will be running at any one time.

You can see a simple test by creating a numpy array or integers and crudely calculating the distance of each value from 50:
import numpy
# Create a random array of 100,000 integers between 0 and 100
a = numpy.random.randint(0, 100, 100_000)
for x in a:
abs(x - 50)
In theory, you would expect (at least with a language like C) that by splitting the work into chunks and distributing the work to threads the execution time would be faster:
import numpy, threading
a = numpy.random.randint(0, 100, 100_000)
threads = []
# Split array into blocks of 100 and start a thread for each
for ar in numpy.split(a, 100):
t = threading.Thread(target=simple_abs_range, args=(ar,))
t.start()
threads.append(t)
for t in threads:
t.join()
In practice the second example is twice as slow. That’s because all those threads are bound to the same GIL and only 1 of them will execute at any time. The extra time is all the song-and-dance to spawn a thread to accomplish very little.
Despite it’s name, the GIL was never really a lock in the interpreter state. PEP684 changed that by stopping the sharing of the GIL between interpreters so that each interpreter in a Python process had it’s own GIL and could therefore run in parallel. A major reason for the per-interpreter GIL working taking many years is that CPython has internally relied upon the GIL as a source of thread-safety. This took the form of many C-Extensions having globally shared state. If you were to introduce a parallelism within the same Python process and two interpreters tried to write to the same memory space, bad things would happen.
In Python 3.12 and ongoing in Python 3.13, the Python standard library extensions written in C are being tested and any global shared state is being moved to a new API that puts that state within either the module, or in the interpreter state. Even when this work is completed, third party C extensions will likely have to test in sub interpreters (I maintain 1 library written in C++ and it required changes).
What about the work to remove the GIL? Doesn’t that make this irrelevant?¶
The very-recently approved proposal, PEP703 to make the GIL optional in CPython works collaboratively with the per-interpreter GIL. Both proposals have the prerequisites:
- Immortal Objects
- Updating C extensions to not use shared global state
Another important point is that whilst PEP703 has been accepted, it was done so with the clause that it is an optional flag, and if it proved too problematic or complex then the changes would be reverted in future. Per-interpreter GIL on the other hand is largely complete and doesn’t require an alternative compile-time flag in CPython.
I will write a lot more about PEP703 in the future. Later in this post I’ll share some code where I’m going to combine the two approaches together.
What is the difference between threading, multiprocessing, and sub interpreters?¶
The Python standard library has a few options for concurrent programming, depending on some factors:
- Is the task you’re completing IO-bound (e.g. reading from a network, writing to disk)
- Does the task require CPU-heavy work, e.g. computation
- Can the tasks be broken into small chunks or are they large pieces of work?
Here are the models:
- Threads are fast to create, you can share any Python objects between them and have a small overhead. Their drawback is that Python threads are bound to the GIL of the process, so if the workload is CPU-intensive then you won’t see any performance gains. Threading is very useful for background, polling tasks like a function that waits and listens for a message on a queue.
- Coroutines are extremely fast to create, you can share any Python objects between them and have a miniscule overhead. Coroutines are ideal for IO-based activity that has an underlying API that supports async/await.
- Multiprocessing is a Python wrapper that creates Python processes and links them together. These processes are slow to start, so the workload that you give them needs to be large enough to see the benefit of parallelising the workload. However, they are truly parallel since each one has it’s own GIL.
- Sub interpreters have the parallelism of multiprocessing, but with a much faster startup time.
I gave a talk on this at PyCon APAC 2023 so check that out for a verbal, detailed explanation.
Or, in a table:
| Model | Execution | Start-up time | Data Exchange |
|---|---|---|---|
| threads | Parallel * | small | Any |
| coroutines | Concurrent | smallest | Any |
| Async functions | Concurrent | smallest | Any |
| Greenlets | Concurrent | smallest | Any |
| multiprocessing | Parallel | large | Serialization |
| Sub Interpreters | Parallel | medium | Serialization or Shared Memory |
* As we explored, Threads are only parallel with IO-bound tasks
How do sub interpreters compare in performance (in real terms)?¶
In a simple benchmark, I measured the time to create:
- 100 threads
- 100 sub interpreters
- 100 processes using multiprocessing
Here are the results:
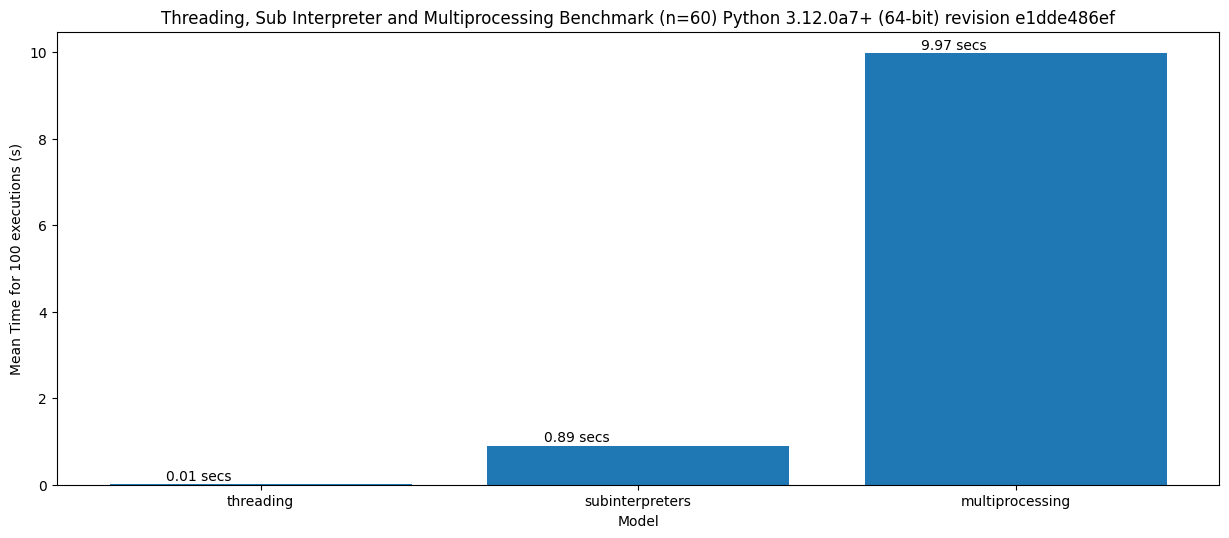
This benchmark showed that threading is about 100 times faster to start than sub interpreters, which are about 10 times faster than multiprocessing. What I’m hoping isn’t lost in this chart is how much closer to threads interpreters are than multiprocessing.
This benchmark also doesn’t measure the performance of data-sharing (which is must faster in sub interpreters than multiprocessing) and the memory overhead (which again is significantly less).
Running nothing in parallel isn’t a very useful benchmark for purposes other than measuring the minimum time to start. Next, I benchmarked a CPU-intensive workload to calculate Pi to 2000 decimal places.
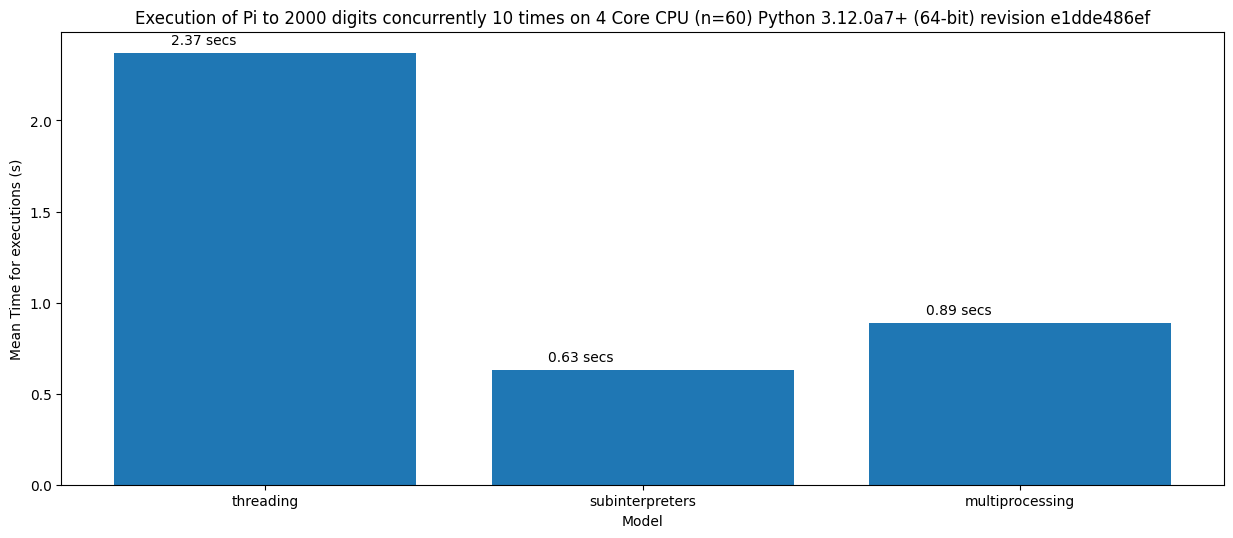
Great! So all parallel workloads will be faster with sub interpreters?¶
Alas no. Going back to the first benchmark, sub interpreters are still 100 times slower to start than threads. So if the task is really small, for example calculating Pi to 200 digits then the benefits of parallelism outweigh the startup overhead and threading is still faster:
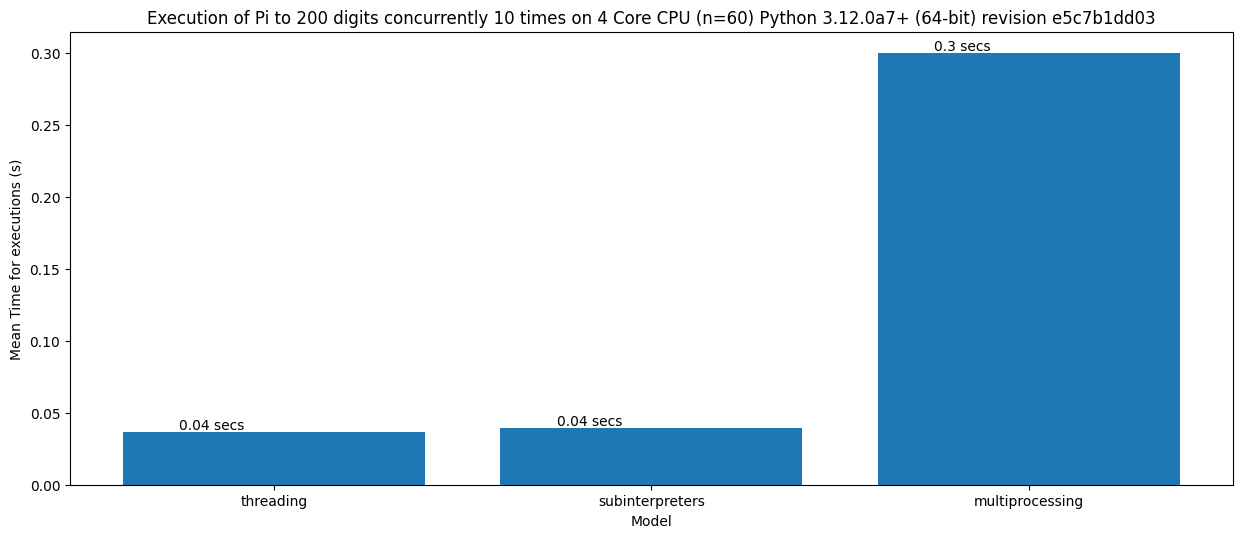
To visually explain the idea of there being a “cut-off” point when parallelism is faster, this graph shows the workload size and the rate of growth for the execution time. The cut-off time isn’t a fixed value because it depends on the CPU, the background tasks and lots of other variances.
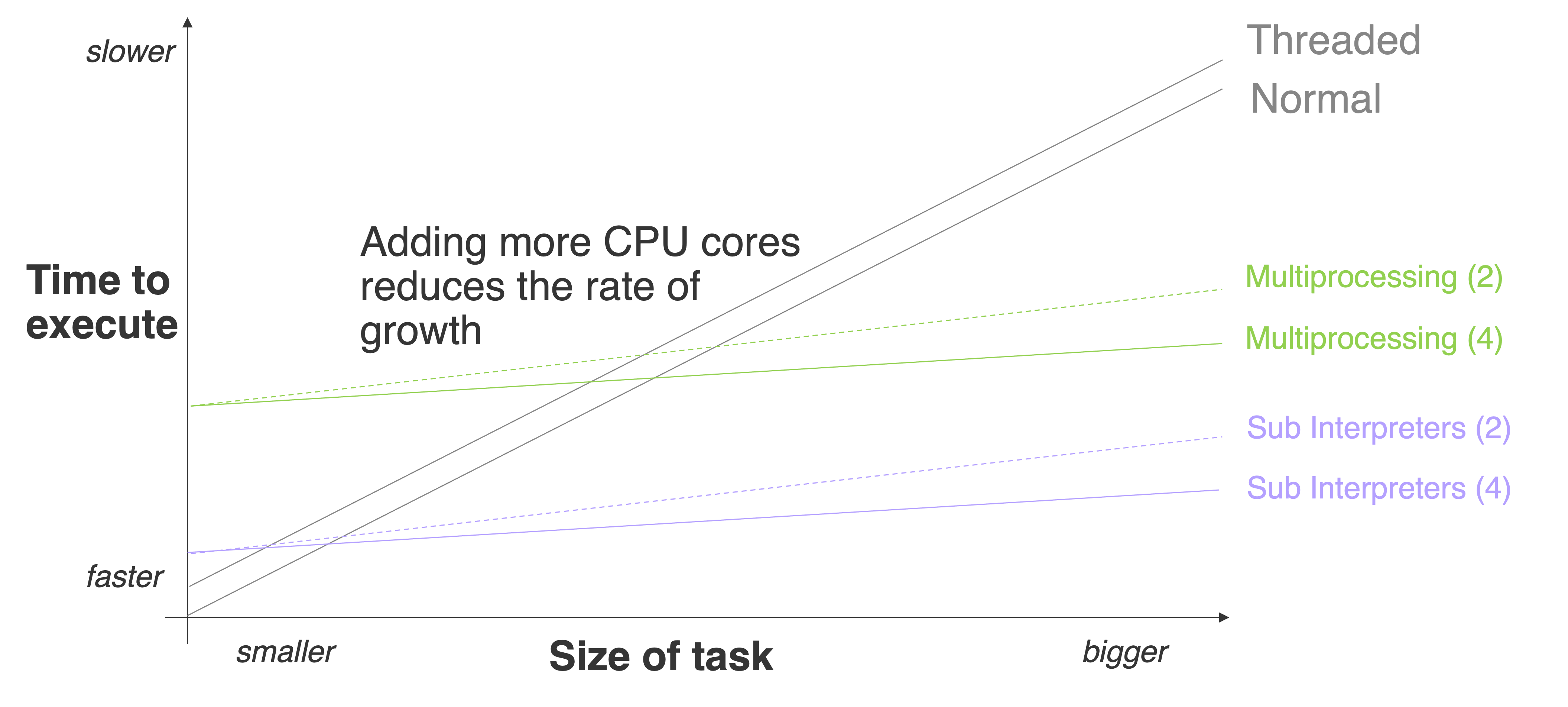
Another important point is that multiprocessing is often used in a model where the processes are long-running and handed lots of tasks instead of being spawned and destroyed for a single workload. One great example is Gunicorn, the popular Python web server. Gunicorn will spawn “workers” using multiprocessing and those workers will live for the lifetime of the main process. The time to start a process or a sub interpreter then becomes irrelevant (at 89 ms or 1 second) when the web worker can be running for weeks, months or years.
The ideal way to use these parallel workers for small tasks (like handle a single web request) is to keep them running and use a main process to coordinate and distribute the workload:
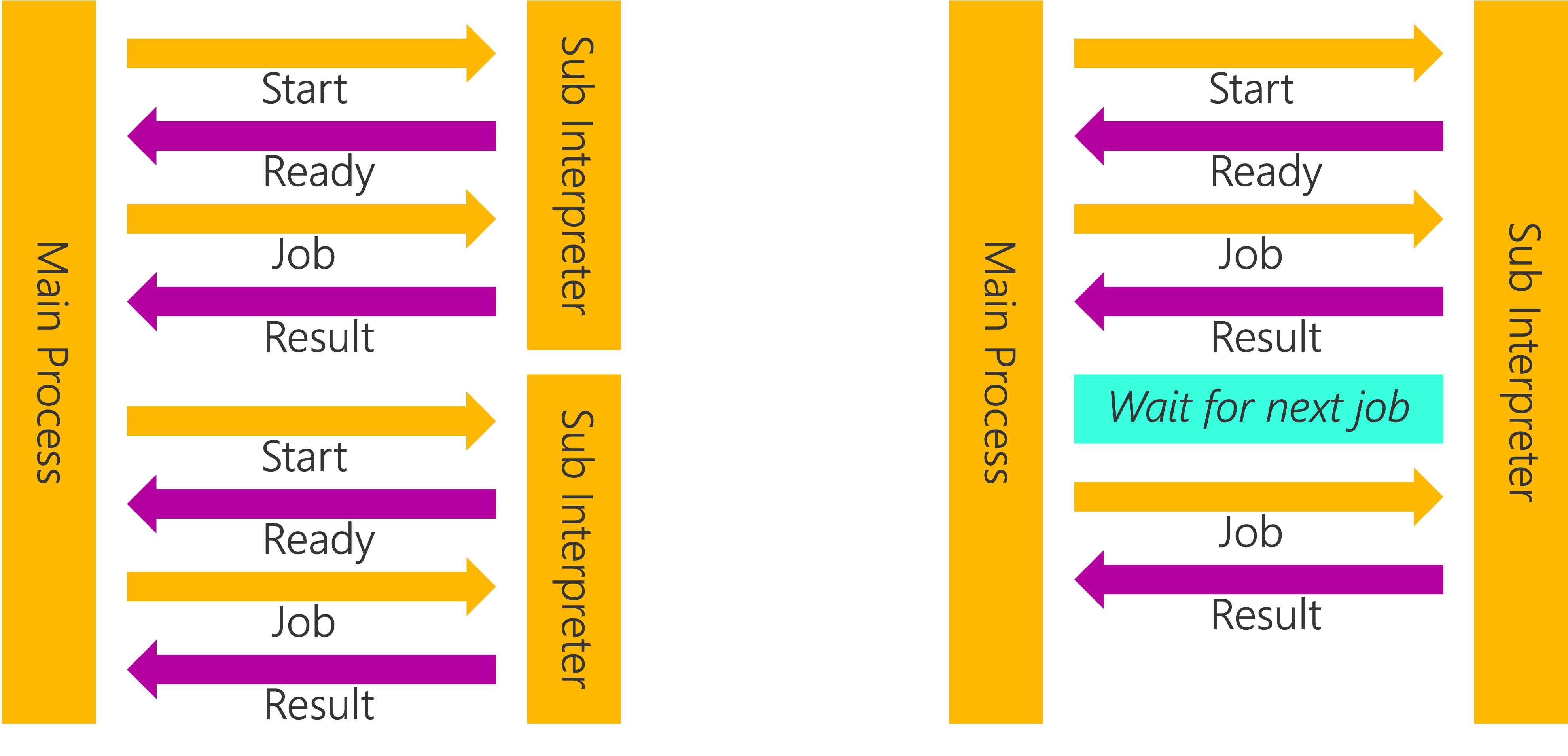
Both multiprocessing processes and interpreters have their own import state. This is drastically different to threads and coroutines. When you await an async function, you don’t need to worry about whether that coroutine has imported the required modules. The same applies for threads. For example, you can import something in your module and reference it from inside the thread function:
import threading
from super.duper.module import cool_function
def worker(info):
cool_function() # This already exists in the interpreter state
info = {'a': 1}
thread = Thread(target=worker, args=(info, ))
Half of the time taken to start an interpreter is taken up running “site import”. This is a special module called site.py that lives within the Python installation. Interpreters have their own caches, their own builtins, they are effectively mini-Python processes. Starting a thread or a coroutine is so fast because it doesn’t have to do any of that work (it shares that state with the owning interpreter), but it’s bound by the lock and isn’t parallel.
Once a interpreter and a process are up and running, does it make a difference to performance?¶
The next point when using a parallel execution model like multiprocessing or sub interpreters is how you share data. Once you get over the hurdle of starting one, this quickly becomes the most important point. You have two questions to answer:
- How do we communicate between workers?
- How do we manage the state of workers?
Let’s address those individually.
Inter-Worker communication¶
Whether using sub interpreters or multiprocessing you cannot simply send existing Python objects to worker processes.
Multiprocessing uses pickle by default. When you start a process or use a process pool, you can use pipes, queues and shared memory as mechanisms to sending data to/from the workers and the main process. These mechanisms revolve around pickling. Pickling is the builtin serialization library for Python that can convert most Python objects into a byte string and back into a Python object.
Pickle is very flexible. You can serialize a lot of different types of Python objects (but not all) and Python objects can even define a method for how they can be serialized. It also handles nested objects and properties. However, with that flexibility comes a performance hit. Pickle is slow. So if you have a worker model that relies upon continuous inter-worker communication of complex pickled data you’ll likely see a bottleneck.
Sub interpreters can accept pickled data. They also have a second mechanism called shared data. Shared data is a high-speed shared memory space that interpreters can write to and share data with other interpreters. It supports only immutable types, those are:
- Strings
- Byte Strings
- Integers and Floats
- Boolean and None
- Tuples (and tuples of tuples)
I implemented the tuple sharing mechanism last week so that we had some option of a sequence type.
To share data with an interpreter, you can either set it as initialization data or you can send it through a channel.
Worker state management¶
This is a work in progress for sub interpreters. If a sub interpreter crashes, it won’t kill the main interpreter. Exceptions can be raised up to the main interpreter and handled gracefully. The details of this are still being worked out.
How do I use a sub interpreter?¶
In Python 3.12, the sub interpreter API is experimental and some of the things I’m going to mention were only implemented a week ago so haven’t been released yet so you’ll see them in future releases of 3.13. If you want to compile the main branch of CPython you can follow along at home.
The interpreters module proposed in PEP554 isn’t finished. A version of it is a secret, hidden module called _xxsubinterpreters. In all my code I rename the import to interpreters because that’s what it’ll be called in future.
You can create, run and stop a sub interpreter with the .run() function which takes a string or a simple function
import _xxsubinterpreters as interpreters
interpreters.run('''
print("Hello World")
''')
Starting a sub interpreter is a blocking operation, so most of the time you want to start one inside a thread.
from threading import Thread
import _xxsubinterpreters as interpreters
t = Thread(target=interpreters.run, args=("print('hello world')",))
t.start()
To start an interpreter that sticks around, you can use interpreters.create() which returns the interpreter ID. This ID can be used for subsequent .run_string calls:
import _xxsubinterpreters as interpreters
interp_id = interpreters.create(site=site)
interpreters.run_string(interp_id, "print('hello world')")
interpreters.run_string(interp_id, "print('hello universe')")
interpreters.destroy(interp_id)
To share data, you can use the shared argument and provide a dictionary with shareable (int, float, bool, bytes, str, None, tuple) values:
import _xxsubinterpreters as interpreters
interp_id = interpreters.create(site=site)
interpreters.run_string(
interp_id,
"print(message)",
shared={
"message": "hello world!"
}
)
interpreters.run_string(
interp_id,
"""
for message in messages:
print(message)
""",
shared={
"messages": ("hello world!", "this", "is", "me")
}
)
interpreters.destroy(interp_id)
Once an interpreter is running (remembering what I said that it is preferable to leave them running) you can share data using a channel. The channels module is also part of PEP554 and available using a secret-import:
import _xxsubinterpreters as interpreters
import _xxinterpchannels as channels
interp_id = interpreters.create(site=site)
channel_id = channels.create()
interpreters.run_string(
interp_id,
"""
import _xxinterpchannels as channels
channels.send('hello!')
""",
shared={
"channel_id": channel_id
}
)
print(channels.recv(channel_id))
Parallel workers in the world of web applications¶
Applying the multiprocessing and threading models to web applications. The Python web servers that sit in front of your framework like Django, Flask, FastAPI or Quart use an interface called WSGI for traditional web frameworks and ASGI for async ones.
The web servers listen on a HTTP port for requests, then divvy up the requests to a pool of workers. If you only had 1 worker, then when a user made a HTTP request, everyone else would have to sit and wait until it finished responding to the first request (this is also why you should never ship python manage.py runserver as the web server because it only has 1 worker).

The recommended best practice for Gunicorn is to run multiple Python processes, coordinated by a main process and for each process to have a pool of threads:
- A number of workers are started using multiprocessing (typically 1 worker for each CPU core)
- A web request is given to a thread pool
This design (sometimes called multi-worker-multi-thread) means that using multiprocessing you have 1 GIL for each CPU Core and you have a pool of threads to handle incoming requests concurrently. Uvicorn, the async implementation builds on that by using coroutines to handle concurrency with frameworks that support async.
There are some downsides to this approach. As we explored earlier, threads are not parallel so if you had 2 threads inside a single worker being very busy, Python can’t “move” or schedule that task on a different CPU core.
Applying sub interpreters to web applications¶
So, my goal is to replace multiprocessing as the mechanism for the workers with an interpreter. This would have the benefit of using the high-performance shared memory channels API for inter-worker communication and the workers would be lighter weight taking up less memory on the host (leaving more memory and resources to process requests).
The second, rather wild goal is to compile CPython 3.13 (main branch) with the PEP703 GIL-less thread implementation to see if we can run GIL-free threads inside this model. I also want to identify issues early and report them upstream (there were a few).
For this experiment, I tried to fork Gunicorn and replace multiprocessing with sub interpreters. What I found was that this would be a huge effort because Gunicorn does have a concept of “workers” and abstracts those in an interface called worker classes. However, it makes some assumptions about the worker class capabilities which sub interpreters don’t fulfill.
Someone on Mastodon suggested I check out Hypercorn, which turned out to be ideal for this test. Hypercorn has an async worker module with a callable that could be imported from inside the interpreter. All I need to work out is:
- How can the workers share the sockets?
- How can I signal a worker to shutdown cleanly (async events won’t work between interpreters)
So, I roughly followed this design:
- Create an interpreter
- Create a signal channel to signal shutdown requests
- Subclass the
threading.Threadclass and implement a custom.stop()method that sends the signal to the sub interpreter - Run each sub interpreter in a thread
- Convert the list of sockets into a tuple of tuples
The worker class looks like this:
class SubinterpreterWorker(threading.Thread):
def __init__(self, number: int, config: Config, sockets: Sockets):
self.worker_number = number
self.interp = interpreters.create()
self.channel = channels.create()
self.config = config # TODO copy other parameters from config
self.sockets = sockets
super().__init__(target=self.run, daemon=True)
def run(self):
# Convert insecure sockets to a tuple of tuples because the Sockets type cannot be shared
insecure_sockets = []
for s in self.sockets.insecure_sockets:
insecure_sockets.append((int(s.family), int(s.type), s.proto, s.fileno()))
interpreters.run_string(
self.interp,
interpreter_worker,
shared={
'worker_number': self.worker_number,
'insecure_sockets': tuple(insecure_sockets),
'application_path': self.config.application_path,
'workers': self.config.workers,
'channel_id': self.channel,
}
)
def stop(self):
print("Sending stop signal to worker {}".format(self.worker_number))
channels.send(self.channel, "stop")
The sub interpreter daemon code (interpreter_worker) is:
import sys
sys.path.append('experiments')
from hypercorn.asyncio.run import asyncio_worker
from hypercorn.config import Config, Sockets
import asyncio
import threading
import _xxinterpchannels as channels
from socket import socket
import time
shutdown_event = asyncio.Event()
def wait_for_signal():
while True:
msg = channels.recv(channel_id, default=None)
if msg == "stop":
print("Received stop signal, shutting down {} ".format(worker_number))
shutdown_event.set()
else:
time.sleep(1)
print("Starting hypercorn worker in subinterpreter {} ".format({worker_number}))
_insecure_sockets = []
# Rehydrate the sockets list from the tuple
for s in insecure_sockets:
_insecure_sockets.append(socket(*s))
hypercorn_sockets = Sockets([], _insecure_sockets, [])
config = Config()
config.application_path = application_path
config.workers = workers
thread = threading.Thread(target=wait_for_signal)
thread.start()
asyncio_worker(config, hypercorn_sockets, shutdown_event=shutdown_event)
The complete code is available on GitHub.
Findings¶
My first cut of this approach still doesn’t have multiple threads inside the sub interpreter (other than the signal thread). I’m building and testing an unstable build of CPython in debug mode. It’s not ready for a comparison performance test - yet.
PEP703 isn’t finished yet. The 100+ todo-list issue in GitHub is about 50% complete. Only at the end of this list can the GIL be disabled.
I also discovered a few issues. Firstly, Django won’t run at all. Remember earlier in this post I mentioned that some Python C extensions use a global shared state? Well, datetime is one of those modules. There is an issue to update it, but it hasn’t been merged yet. The consequence is that if you import zoneinfo from a sub interpreter, it will fail. Django uses zoneinfo, so it doesn’t even start.
I did have more luck with a very crude FastAPI and Flask application. I was able to launch a 2, 4 and 10 worker setup with those applications. I did run a few benchmarks on the FastAPI and Flask applications to see that it handled 10,000 requests with a concurrency of 20. Both performed admirably with all my CPU cores beavering away.
I was pleasantly suprised since I wasn’t expecting it to work at all because sub interpreters are so new and the Python ecosystem hasn’t been testing them. The next step is to test some more complex web applications, continue to report crashes and issues then get this web worker into a state where it’s stable enough to benchmark.
Then I might just submit a PR to Hypercorn for Python 3.13’s release next year.

Related Posts


